☑️ DSML: MLOps Lifecycle Checklist
A validated and novice-friendly master checklist for the DSML lifecycle — Plan, Data, Model, and Deploy — aligned with Google, AWS, and Microsoft MLOps frameworks.
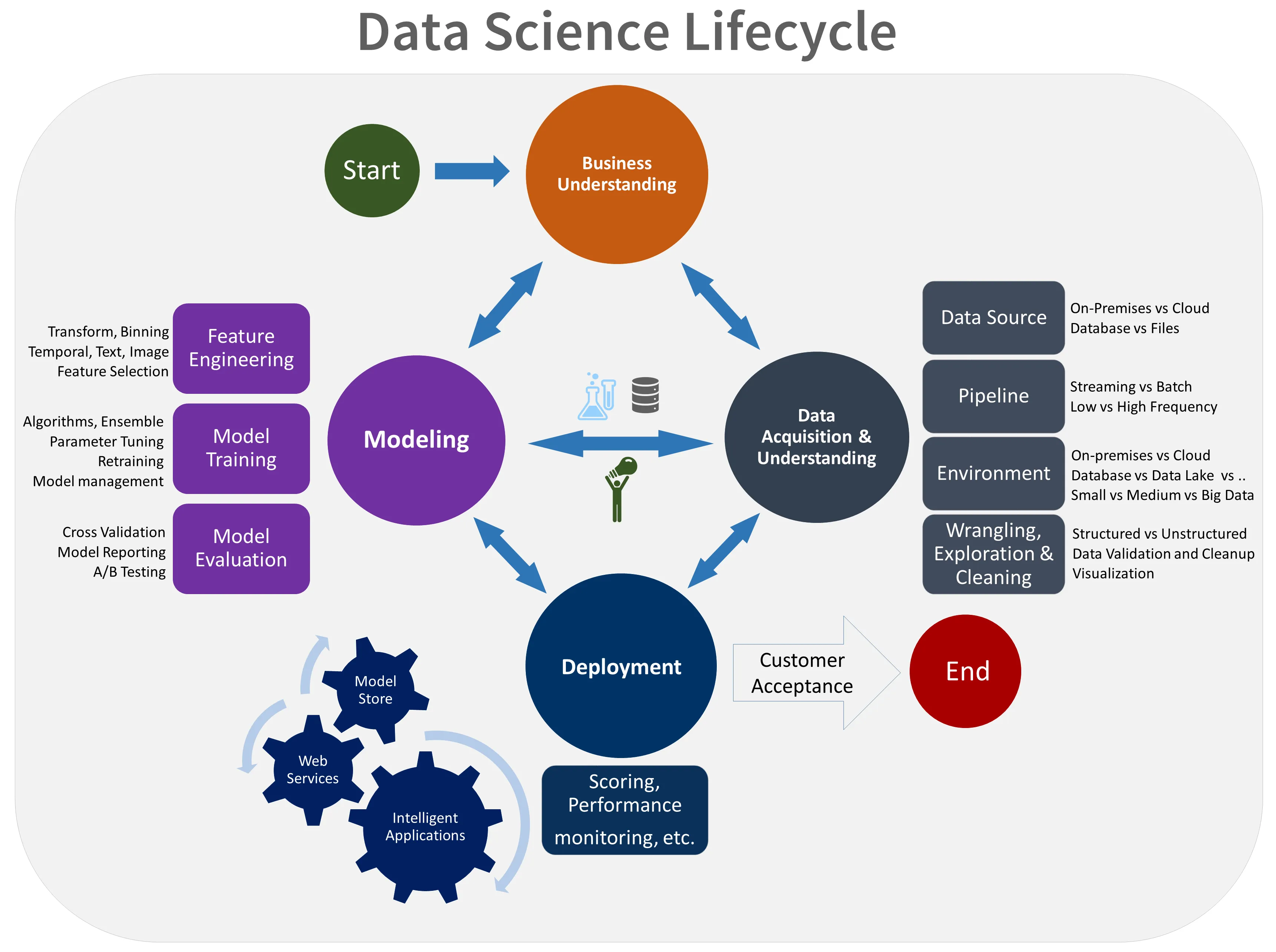
☑️ DSML: MLOps Lifecycle Checklist
Plan → Data → Model → Deploy
🧭 A complete, validated, and easy-to-follow roadmap of the Machine Learning lifecycle — harmonized from Google, AWS, Microsoft, Deepchecks, and Neptune.ai frameworks.
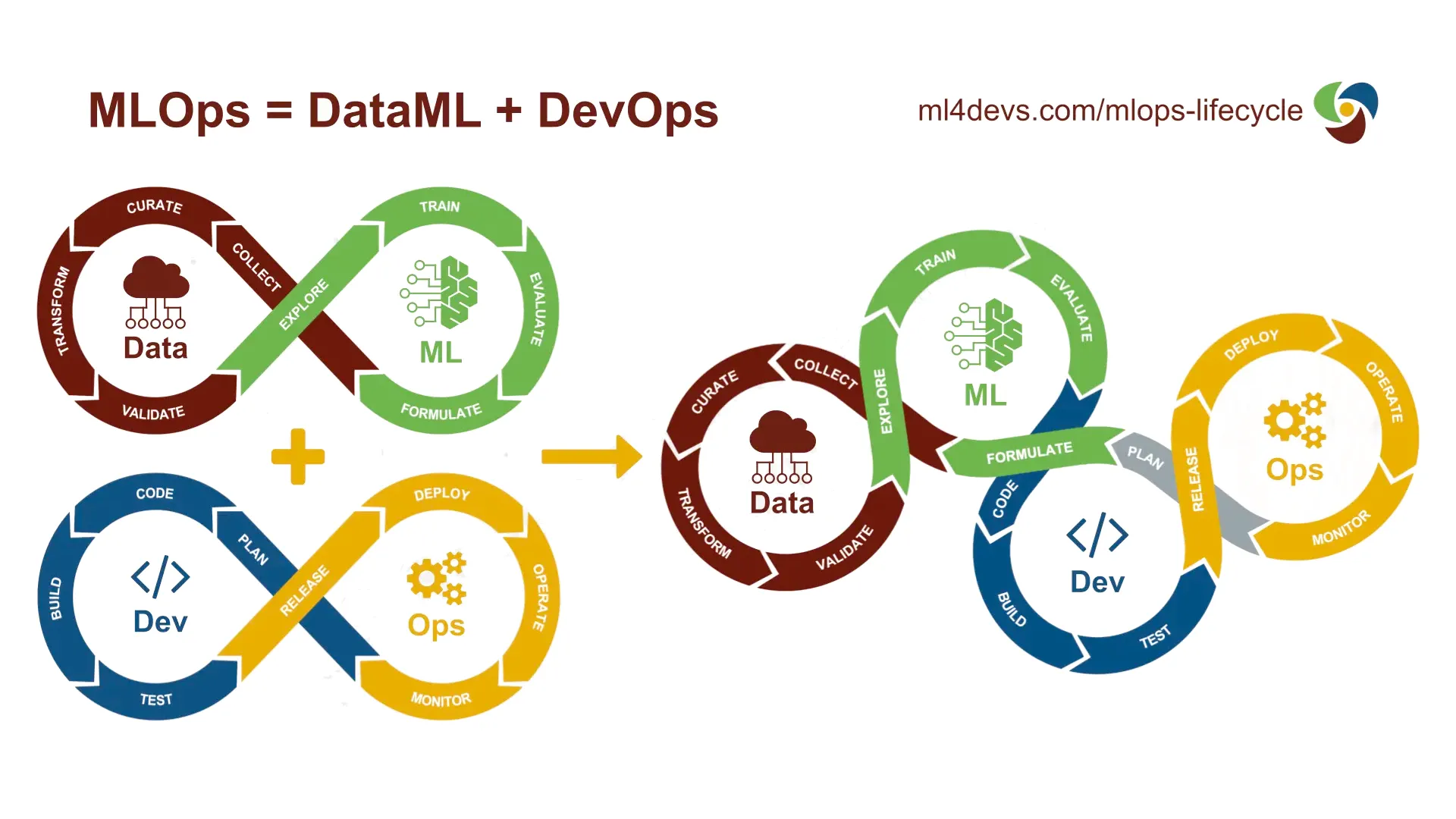 MLOps Illustrated: MLOps = Data + ML + Dev + Sec + Ops
MLOps Illustrated: MLOps = Data + ML + Dev + Sec + Ops
🧭 Phase 1: Plan — Planning & Scoping
Define the problem, align stakeholders, assess feasibility, and establish the project roadmap.
| Icon | Checklist Item | Explanation |
|---|---|---|
| 🎯 | Business Objective Defined | Clarify what business outcome or decision the model supports. Define measurable KPIs (e.g., reduce churn by 10%). |
| 👥 | Stakeholders Mapped | Identify owners, contributors, reviewers, and end users for full accountability. |
| 🧮 | Baseline / Benchmark Established | Define a simple rule-based or non-ML baseline for measuring improvement. |
| 📐 | ML Task Framed | Translate business needs into ML paradigms (classification, regression, clustering, recommendation). |
| 📊 | Success Metrics Chosen | Pick both technical metrics (AUC, RMSE) and business metrics (ROI, revenue uplift). |
| 🗂️ | Data Availability & Quality Assessed | Inventory potential data sources, check for completeness, accessibility, and reliability. |
| 🔗 | Infrastructure & Tooling Decided | Select your ML stack (frameworks, pipelines, versioning, compute environment). |
| 🗓️ | Roadmap & Milestones Set | Define phase-wise deliverables, cost, and schedule using agile or Kanban tracking. |
| ⚠️ | Risk, Ethics & Governance Reviewed | Address privacy, fairness, and compliance (PII, GDPR). Document known risks and mitigations. |
| ✅ | Go/No-Go Gate Passed | Ensure alignment with stakeholders, feasibility confirmed, and approval obtained before proceeding. |
🧪 Phase 2: Data — Preparation & Understanding
Acquire, prepare, explore, and validate data before modeling.
| Icon | Checklist Item | Explanation |
|---|---|---|
| 🚚 | Data Ingestion Completed | Gather raw data via APIs, databases, logs, sensors, or files (batch/stream). |
| 🔍 | Data Profiling & Understanding Done | Inspect schemas, distributions, nulls, correlations, and summary stats. |
| 🧼 | Data Cleaning & Conditioning | Handle missing values, duplicates, outliers, incorrect data types, and unit inconsistencies. |
| 📐 | Data Transformation & Feature Engineering | Normalize, encode, scale, and generate new features (aggregations, ratios, embeddings). |
| 🧮 | Feature Selection & Dimensionality Reduction | Retain key features (filter/wrapper/embedded), apply PCA or UMAP where appropriate. |
| 📊 | Exploratory Data Analysis (EDA) Conducted | Visualize data relationships, trends, and anomalies; check for leakage or imbalance. |
| 🏷️ | Labeling / Annotation Completed | For supervised tasks: ensure accurate and consistent labels with quality checks. |
| 📦 | Data Validation & Storage Versioned | Validate schema and splits; store versioned datasets in a governed data lake/warehouse. |
| 🔄 | Data Observability & Drift Pipeline Defined | Plan continuous monitoring for data quality, freshness, and drift detection post-deployment. |
🤖 Phase 3: Model — Building, Evaluation & Packaging
Build, evaluate, optimize, and prepare models for deployment with full traceability.
| Icon | Checklist Item | Explanation |
|---|---|---|
| 🔍 | Algorithm Candidates Selected | Choose appropriate models based on data size, interpretability, and latency constraints. |
| ⚙️ | Training Pipeline Built & Tracked | Modularize code (fit, predict, evaluate); use experiment trackers (MLflow, W&B, Comet). |
| 🔄 | Model Training & Cross-Validation Executed | Train using k-fold, time-series, or stratified splits; evaluate over multiple seeds. |
| 📉 | Hyperparameter Tuning Performed | Optimize via grid/random/Bayesian search; use early stopping and parallelization. |
| 📊 | Model Evaluation & Diagnostics Completed | Compute metrics, check for bias, calibration, overfitting, and robustness to perturbations. |
| 🎯 | Model Selection & Champion Chosen | Compare performance, interpretability, and efficiency; register best candidate. |
| 🛠️ | Model Serialization & Packaging Done | Save model artifacts, preprocessing code, configs, and environment dependencies. |
| 🧪 | Pre-Deployment Testing Passed | Perform integration, latency, and reproducibility tests; shadow or A/B test if feasible. |
| 📜 | Documentation & Model Card Prepared | Summarize purpose, data used, performance, risks, and limitations per model card format. |
🚀 Phase 4: Deploy — Productionization & Lifecycle Management
Move validated models into production and establish monitoring, retraining, and governance.
| Icon | Checklist Item | Explanation |
|---|---|---|
| ⚙️ | Deployment Strategy Adopted | Choose mode: batch, online API, streaming, edge, or hybrid; define rollout plan. |
| 🧱 | CI/CD & IaC Pipelines Implemented | Automate testing, packaging, and deployment via GitHub Actions, Jenkins, or ArgoCD. |
| 🖥️ | Model Serving Layer Live | Deploy REST/gRPC API; validate request schemas, latency, and logging. |
| 📈 | Monitoring & Observability Activated | Track performance, latency, error rates, data drift, and business metrics. |
| 🔁 | Retraining Pipeline Implemented | Automate retraining triggers (schedule or drift-based) with version control and human review. |
| 🛡️ | Security & Governance Enforced | Manage access, encrypt data, log usage, enforce compliance and fairness checks. |
| 🔧 | Rollback & Fallback Mechanism Ready | Define safe fallback (baseline model or previous version) for automatic rollback. |
| 📚 | Documentation & Runbook Finalized | Include incident response, maintenance procedures, version notes, and contact matrix. |
| 📊 | Post-Deployment Review Conducted | Compare live KPIs vs. planned metrics; confirm value realization and feedback into planning. |
🔄 Lifecycle Summary Flow
PLAN → DATA → MODEL → DEPLOY → (Monitoring/Feedback) → PLAN
- Iterative feedback loops occur especially between:
- Model ↔ Data (feature drift, retraining)
- Deploy ↔ Model (concept drift, monitoring insights)
- Deploy ↔ Plan (business realignment)
⚙️ Canonical Jargon Reference
| Term | Meaning |
|---|---|
| Feature Engineering | Creating or transforming data attributes to improve model learning. |
| Drift | Change in data or concept distributions over time affecting model accuracy. |
| Model Card | Standardized documentation summarizing model purpose, performance, and ethical considerations. |
| CI/CD | Continuous Integration / Continuous Deployment — automated testing and rollout pipelines. |
| IaC | Infrastructure as Code — declaratively managing resources for reproducible environments. |
✅ Phase Exit Gates (for Governance)
| Phase | Exit Criteria |
|---|---|
| Plan | Business goals, feasibility, risks, and success metrics approved. |
| Data | Clean, validated, versioned data ready for modeling. |
| Model | Champion model validated, reproducible, and documented. |
| Deploy | CI/CD automated, monitoring active, governance verified. |
⚠️ Common Pitfalls & Remedies
| Pitfall | Impact | Remedy |
|---|---|---|
| Unclear business objective | Misaligned outcomes | Write SMART goals and measurable KPIs |
| Unversioned data/models | Non-reproducible results | Use DVC/MLflow registry |
| Over-tuned model | Overfitting / poor generalization | Use cross-validation and baseline comparison |
| Manual deployment | High risk of errors | Automate CI/CD pipeline |
| No drift monitoring | Model silently degrades | Implement data + concept drift detection |
| Missing rollback | Unrecoverable failure | Use canary/blue-green strategy |
🔗 Trusted References
- Google Cloud: MLOps Continuous Delivery Guide
- AWS SageMaker: Model Deployment & Monitoring
- Microsoft TDSP: Data Science Process
- Deepchecks: ML Lifecycle
- Neptune.ai: ML Project Lifecycle
- Analytics Vidhya: Machine Learning Lifecycle Explained
🧩 Key Insight
“Successful ML systems are not about the best model — they are about the best lifecycle.”
— Adapted from Google ML Engineering Playbook
⭐ Author’s Note:
This checklist is designed for DS/ML practitioners and educators seeking a clear, canonical lifecycle reference — ready for integration into MLOps pipelines, project templates, or portfolio documentation.