🧭 Databases 101: Quick Guide & References
Databases - A Quick Guide - Complete Functional Categorization, Best Choices, Differences, Cloud Support, Python Connectivity & Analytical Comparison!

Databases 101 Resources
Databases 101
Databases - Complete Functional Categorization, Best Choices, Differences, Cloud Support, Python Connectivity & Analytical Comparison — A Deep Dive!
Introduction
Databases are the backbone of modern applications, storing and managing data for everything from simple mobile apps to complex enterprise systems. This comprehensive guide will walk you through the entire database landscape, helping you understand what databases are, how they differ, and which one to choose for your specific needs.
1. Foundations
What Are Databases?
A database is an organized collection of structured data stored electronically. It allows you to store, retrieve, update, and manage data efficiently. Databases use specialized software called Database Management Systems (DBMS) to handle these operations.
Think of a database as a digital filing cabinet where information is organized in a way that makes it easy to find and use.
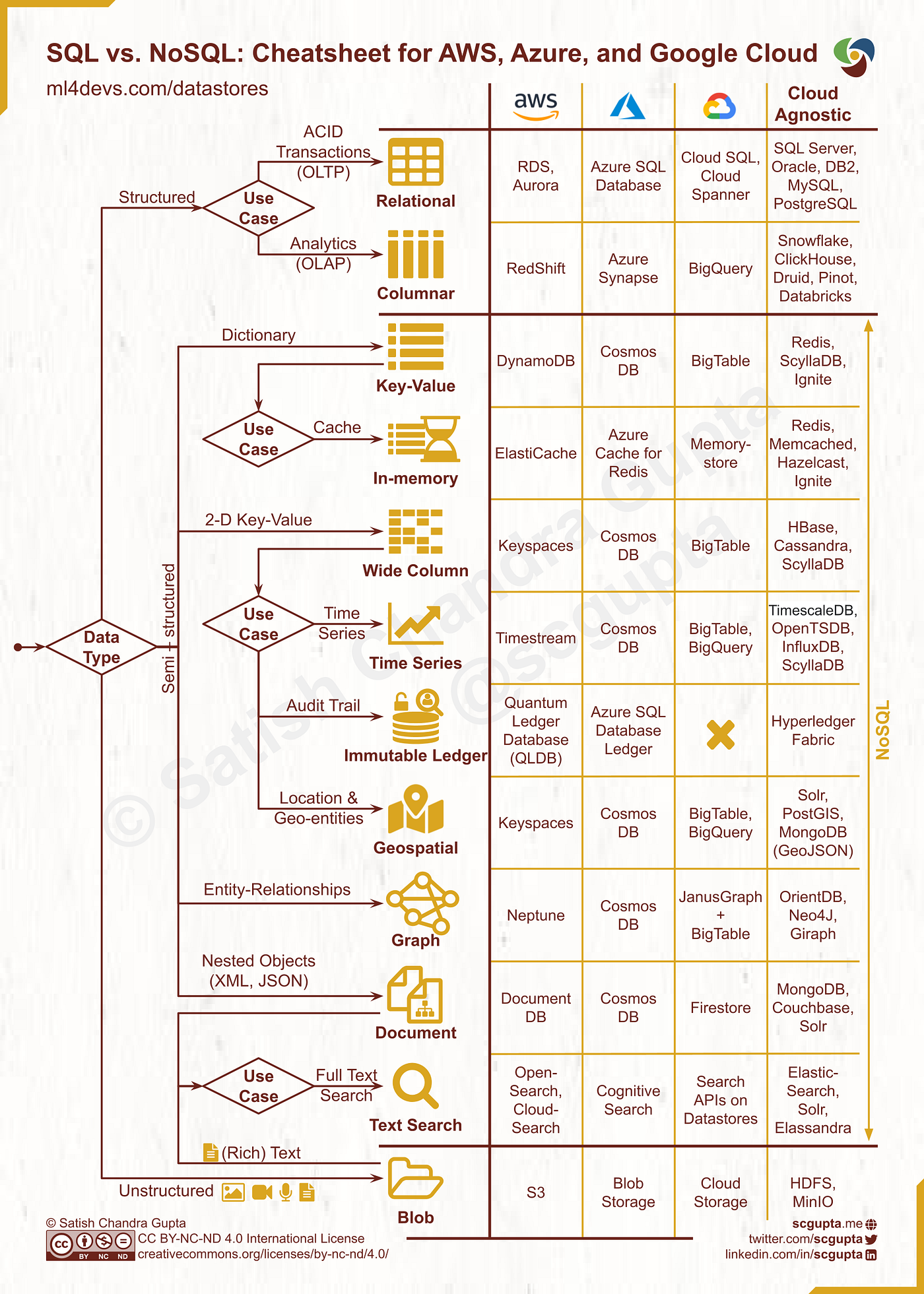
SQL vs NoSQL
SQL (Structured Query Language) Databases:
- Store data in tables with predefined schemas (structure)
- Enforce relationships between tables using foreign keys
- Follow ACID properties (Atomicity, Consistency, Isolation, Durability)
- Best for structured data with clear relationships
- Examples: PostgreSQL, MySQL, Oracle
NoSQL (Not Only SQL) Databases:
- Store data in flexible formats (documents, key-value pairs, graphs, wide columns)
- No fixed schema—structure can change over time
- Prioritize scalability and performance over strict consistency
- Best for unstructured or semi-structured data
- Examples: MongoDB, Redis, Cassandra
OLTP vs OLAP
OLTP (Online Transaction Processing):
- Handles day-to-day operational transactions (create, read, update, delete)
- Optimized for frequent, small queries
- Supports many concurrent users
- Maintains data integrity and consistency
- Examples: Banking systems, e-commerce platforms, inventory management
- Representative databases: PostgreSQL, MySQL
OLAP (Online Analytical Processing):
- Handles complex analytical queries across large datasets
- Optimized for reading and aggregating data
- Used for reporting, business intelligence, data mining
- Fewer concurrent users, but queries process millions of rows
- Examples: Sales analysis, trend forecasting, data warehousing
- Representative databases: Snowflake, BigQuery, ClickHouse
Embedded vs Server vs Cloud-Managed
Embedded Databases:
- Run inside your application process (no separate server)
- Stored as a file or in-memory
- Zero configuration, no network overhead
- Examples: SQLite, DuckDB
- Use case: Mobile apps, desktop software, prototyping
Server Databases:
- Run as separate processes on dedicated servers
- Multiple applications connect over a network
- Support concurrent access from many users
- Examples: PostgreSQL, MongoDB, MySQL
- Use case: Web applications, enterprise systems
Cloud-Managed Databases:
- Hosted and managed by cloud providers
- Automatic backups, scaling, updates, and monitoring
- Pay-as-you-go pricing
- Examples: Amazon RDS, MongoDB Atlas, Snowflake
- Use case: When you want to focus on building apps, not managing infrastructure
2. Functional Categorization
2.1 Relational Databases (SQL / RDBMS)
What It Is: Traditional databases that organize data into tables with rows and columns. Tables are linked through relationships (foreign keys), ensuring data integrity and consistency.
Core Characteristics:
- Structured schema defined upfront
- ACID-compliant transactions
- SQL query language
- Strong data integrity with constraints
- Excellent for complex joins and relationships
Cloud Availability:
- Amazon RDS (PostgreSQL, MySQL, MariaDB)
- Google Cloud SQL
- Azure Database for PostgreSQL/MySQL
- DigitalOcean Managed Databases
Python Connectivity:
psycopg2orpsycopg3(PostgreSQL)mysql-connector-python(MySQL)pymysql(MySQL)- SQLAlchemy (ORM for multiple databases)
Typical Use Cases:
- E-commerce platforms
- Financial systems
- Customer relationship management (CRM)
- Enterprise resource planning (ERP)
- Any application requiring complex queries and data integrity
2.2 Distributed SQL / NewSQL
What It Is: Modern databases that combine SQL semantics with horizontal scalability. They distribute data across multiple nodes while maintaining ACID guarantees.
Core Characteristics:
- SQL interface with NoSQL-like scalability
- Automatic sharding and replication
- Strong consistency across distributed nodes
- Horizontal scaling without application changes
- High availability and fault tolerance
Cloud Availability:
- Google Cloud Spanner
- CockroachDB Cloud
- YugabyteDB Managed
- Amazon Aurora (proprietary distributed SQL)
Python Connectivity:
google-cloud-spanner(Cloud Spanner)psycopg2(CockroachDB—PostgreSQL compatible)psycopg2(YugabyteDB—PostgreSQL compatible)
Typical Use Cases:
- Global applications requiring strong consistency
- Financial transactions at scale
- Gaming leaderboards and inventory systems
- SaaS platforms with multi-region deployment
- Applications outgrowing single-server databases
2.3 Document Databases
What It Is: Databases that store data as JSON-like documents (BSON in MongoDB). Each document is self-contained and can have a different structure.
Core Characteristics:
- Flexible schema—no predefined structure required
- Documents grouped in collections
- Nested data structures supported natively
- Horizontal scaling through sharding
- Rich query capabilities including aggregations
Cloud Availability:
- MongoDB Atlas
- Amazon DocumentDB
- Azure Cosmos DB (document API)
- Couchbase Cloud
Python Connectivity:
pymongo(MongoDB)couchbase(Couchbase)- Motor (async MongoDB driver)
Typical Use Cases:
- Content management systems
- User profiles and preferences
- Product catalogs with varying attributes
- Real-time analytics
- Mobile and web applications with evolving data models
2.4 Key-Value Stores
What It Is: The simplest NoSQL model—stores data as unique keys paired with values. Think of it as a giant dictionary or hash map.
Core Characteristics:
- Extremely fast reads and writes
- Simple data model (key → value)
- Often in-memory for ultra-low latency
- Horizontal scaling
- Limited query capabilities (no complex queries)
Cloud Availability:
- Redis Enterprise Cloud
- Amazon ElastiCache
- Azure Cache for Redis
- Google Cloud Memorystore
Python Connectivity:
redis-py(Redis)boto3(Amazon DynamoDB)
Typical Use Cases:
- Session management
- Caching layers
- Real-time recommendations
- Leaderboards and counters
- Message queues and pub/sub systems
- Rate limiting
2.5 Wide-Column Stores
What It Is: Databases that store data in columns rather than rows, optimized for queries that access many rows but few columns. Data is organized into column families.
Core Characteristics:
- Columns grouped into families
- Sparse data support (not all columns need values)
- Horizontal scaling across commodity hardware
- High write throughput
- Optimized for time-series and analytical workloads
Cloud Availability:
- Google Cloud Bigtable
- Amazon Keyspaces (Cassandra)
- Azure Cosmos DB (Cassandra API)
- DataStax Astra (managed Cassandra)
Python Connectivity:
google-cloud-bigtable(Bigtable)cassandra-driver(Cassandra)
Typical Use Cases:
- Time-series data (IoT sensor data, logs)
- Event tracking and analytics
- Recommendation engines
- Financial market data
- Large-scale telemetry
- User activity tracking
2.6 Graph Databases
What It Is: Databases designed to store and query relationships between entities. Data is represented as nodes (entities) and edges (relationships).
Core Characteristics:
- Native graph storage and processing
- Relationships are first-class citizens
- Optimized for traversing connected data
- Supports complex relationship queries
- Pattern matching and pathfinding
Cloud Availability:
- Neo4j AuraDB
- Amazon Neptune
- Azure Cosmos DB (Gremlin API)
- TigerGraph Cloud
Python Connectivity:
neo4j(Neo4j driver)gremlinpython(Gremlin/TinkerPop)py2neo(Neo4j)
Typical Use Cases:
- Social networks (friends, followers, connections)
- Fraud detection
- Recommendation engines
- Knowledge graphs
- Network and IT infrastructure mapping
- Supply chain optimization
2.7 Time-Series Databases
What It Is: Specialized databases optimized for timestamped data. Designed for write-heavy workloads with time-based queries and aggregations.
Core Characteristics:
- Automatic data retention policies
- Time-based indexing and partitioning
- High write throughput
- Built-in downsampling and aggregation
- Compression optimized for temporal data
Cloud Availability:
- InfluxDB Cloud
- Amazon Timestream
- Azure Data Explorer
- TimescaleDB Cloud (PostgreSQL extension)
Python Connectivity:
influxdb-client(InfluxDB)boto3(Amazon Timestream)psycopg2(TimescaleDB)
Typical Use Cases:
- IoT sensor monitoring
- Application performance monitoring (APM)
- DevOps metrics and observability
- Financial tick data
- Server and infrastructure monitoring
- Industrial equipment telemetry
2.8 Search / Log Analytics Engines
What It Is: Databases optimized for full-text search, log aggregation, and real-time analytics. Built on inverted indexes for lightning-fast search.
Core Characteristics:
- Full-text search with ranking
- Real-time indexing
- Aggregations and analytics
- Distributed architecture
- Schema flexibility
Cloud Availability:
- Elastic Cloud
- Amazon OpenSearch Service
- Azure Cognitive Search
- Algolia (specialized search)
Python Connectivity:
elasticsearch(Elasticsearch)opensearch-py(OpenSearch)
Typical Use Cases:
- Log and event aggregation
- Application search features
- Security information and event management (SIEM)
- E-commerce product search
- Business metrics dashboards
- Real-time analytics on streaming data
2.9 Data Warehouses / OLAP
What It Is: Large-scale analytical databases designed for complex queries across massive datasets. Optimized for read-heavy analytical workloads.
Core Characteristics:
- Columnar storage for fast aggregations
- Massively parallel processing (MPP)
- Separation of storage and compute
- Handles petabyte-scale data
- Optimized for SQL analytics
Cloud Availability:
- Snowflake
- Google BigQuery
- Amazon Redshift
- Azure Synapse Analytics
- Databricks SQL
Python Connectivity:
snowflake-connector-python(Snowflake)google-cloud-bigquery(BigQuery)redshift-connector(Redshift)
Typical Use Cases:
- Business intelligence and reporting
- Data science and machine learning
- Historical data analysis
- Customer behavior analytics
- Financial reporting and forecasting
- Executive dashboards
2.10 Multi-Model Databases
What It Is: Databases that support multiple data models (document, graph, key-value, column-family) in a single system, allowing different access patterns.
Core Characteristics:
- Single database for multiple data models
- Different APIs for different models
- Global distribution with multi-region replication
- Flexible consistency levels
- Unified management
Cloud Availability:
- Azure Cosmos DB
- ArangoDB Cloud
- Amazon DynamoDB (document + key-value)
- OrientDB Cloud
Python Connectivity:
azure-cosmos(Azure Cosmos DB)python-arango(ArangoDB)boto3(DynamoDB)
Typical Use Cases:
- Complex applications with diverse data needs
- Migrating from multiple databases
- Global applications requiring multi-region access
- Applications needing both transactions and analytics
- Reducing operational complexity
2.11 Embedded Analytic Engines
What It Is: Lightweight, embeddable databases that run in-process, designed for analytical queries (OLAP) on local datasets without server overhead.
Core Characteristics:
- Zero configuration and deployment
- In-process execution (no network latency)
- Columnar storage and vectorized execution
- Optimized for analytical queries
- Read-optimized with transaction support
Cloud Availability:
- Not traditionally cloud-hosted (embedded nature)
- Can be deployed in cloud VMs or containers
- DuckDB can query cloud storage directly (S3, GCS)
Python Connectivity:
duckdb(DuckDB)sqlite3(SQLite, built into Python)
Typical Use Cases:
DuckDB:
- Data analysis in Python/R notebooks
- ETL and data transformation pipelines
- Querying Parquet, CSV, JSON files
- In-memory analytics on medium-sized datasets
- Embedded analytics in desktop applications
SQLite:
- Mobile and desktop applications
- Embedded device storage
- Application configuration storage
- Browser storage (via WASM)
- Prototyping and testing
- Simple file-based data persistence
3. Best Database in Each Category
3.1 Best Relational Database: PostgreSQL
Why It’s the Best: PostgreSQL is the most advanced open-source relational database, combining decades of reliability with cutting-edge features. It’s the gold standard for RDBMS.
Strengths & Differentiators:
- Extensibility: Custom data types, functions, operators, and extensions
- Advanced features: JSON/JSONB support, full-text search, geospatial (PostGIS), arrays
- Standards compliance: Most SQL:2016 compliant database
- Performance: Excellent query optimizer, parallel queries, partitioning
- ACID guarantees: Rock-solid transaction support
- Community: Massive ecosystem of tools and extensions
- Versatility: Handles OLTP, light OLAP, document storage, graph queries
Cloud Availability:
- Amazon RDS for PostgreSQL
- Google Cloud SQL for PostgreSQL
- Azure Database for PostgreSQL
- DigitalOcean Managed PostgreSQL
- Aiven for PostgreSQL
Python Driver:
psycopg3(modern, recommended)psycopg2(mature, widely used)- SQLAlchemy (ORM support)
Ideal Use Cases:
- Web applications requiring complex queries
- Financial systems needing ACID compliance
- Applications with evolving schemas (JSONB flexibility)
- Geospatial applications
- Multi-tenant SaaS platforms
- Any project valuing stability and feature richness
Core Advantages:
- Zero vendor lock-in (open source)
- Exceptional documentation
- Proven reliability at scale
- Handles both structured and semi-structured data
- Strong security features
3.2 Best Distributed SQL: Google Cloud Spanner
Why It’s the Best: Cloud Spanner is the only database that provides global consistency, horizontal scalability, and 99.999% availability SLA—all while maintaining full SQL semantics and ACID guarantees.
Strengths & Differentiators:
- True global consistency: Strong consistency across regions using TrueTime
- Unlimited scale: Automatic sharding and rebalancing
- 99.999% availability: Built-in redundancy and failover
- ACID transactions: Even across distributed nodes
- SQL interface: Standard SQL with extensions
- No manual sharding: Fully managed scaling
Cloud Availability:
- Google Cloud Platform (native)
- Available in 30+ regions globally
Python Driver:
google-cloud-spanner- Django and SQLAlchemy support available
Ideal Use Cases:
- Global financial services and payment systems
- Multi-region SaaS applications
- Gaming backends with global leaderboards
- Supply chain management
- Any application requiring both scalability and strong consistency
- Mission-critical systems with zero downtime requirements
Core Advantages:
- Externally consistent transactions
- No operational burden (fully managed)
- Seamless scaling without downtime
- Automatic replication and backups
- Enterprise-grade security
3.3 Best Document Database: MongoDB Atlas
Why It’s the Best: MongoDB Atlas is the most mature and feature-rich document database, offering unmatched flexibility, scalability, and developer experience.
Strengths & Differentiators:
- Flexible schema: Evolve data models without migrations
- Rich query language: Aggregation framework, joins, transactions
- Horizontal scaling: Built-in sharding across nodes
- ACID transactions: Multi-document transactions across shards
- Global clusters: Automatic data distribution by geography
- Developer experience: Intuitive API, excellent documentation
- Search integration: Built-in full-text search (Atlas Search)
- Time-series: Native time-series collections
Cloud Availability:
- MongoDB Atlas (AWS, Azure, GCP)
- Available in 100+ regions globally
Python Driver:
pymongo(synchronous)motor(asynchronous)- ODMs: MongoEngine, Beanie
Ideal Use Cases:
- Content management systems
- Mobile and IoT applications
- Real-time analytics
- Product catalogs
- User profiles and personalization
- Rapid prototyping and agile development
- Applications with frequently changing requirements
Core Advantages:
- Fastest time to market
- Scales horizontally with ease
- Change-friendly architecture
- Strong consistency with flexibility
- Comprehensive tooling ecosystem
3.4 Best Key-Value Store: Redis Enterprise Cloud
Why It’s the Best: Redis Enterprise Cloud combines the raw speed of in-memory computing with enterprise features like durability, clustering, and Active-Active replication.
Strengths & Differentiators:
- Sub-millisecond latency: In-memory performance
- Rich data structures: Strings, hashes, lists, sets, sorted sets, streams, bitmaps
- Persistence options: RDB snapshots and AOF logs
- Active-Active replication: Multi-region writes with conflict resolution
- 99.999% uptime: Enterprise-grade reliability
- Auto-scaling: Automatic capacity management
- Modules: RedisJSON, RedisSearch, RedisGraph, RedisTimeSeries
Cloud Availability:
- Redis Enterprise Cloud (multi-cloud)
- Amazon ElastiCache for Redis
- Azure Cache for Redis
- Google Cloud Memorystore
Python Driver:
redis-pyaioredis(async)
Ideal Use Cases:
- Session storage
- Real-time caching
- Leaderboards and counters
- Message queues (Redis Streams)
- Real-time analytics
- Rate limiting and throttling
- Pub/sub messaging
- Machine learning model serving
Core Advantages:
- Unmatched speed
- Versatile data structures
- Proven at massive scale
- Simple yet powerful
- Strong community and ecosystem
3.5 Best Wide-Column Store: Google Cloud Bigtable
Why It’s the Best: Bigtable is the original wide-column database (paper published 2006), powering Google Search, Gmail, and Google Analytics. It’s battle-tested at planetary scale.
Strengths & Differentiators:
- Massive throughput: Millions of operations per second
- Low latency: Single-digit millisecond latency at scale
- Proven scalability: Petabyte-scale deployments
- Seamless scaling: Add nodes without downtime
- Integration: Native with Google Cloud services (Dataflow, BigQuery)
- HBase compatibility: Easy migration from HBase
Cloud Availability:
- Google Cloud Platform (native)
Python Driver:
google-cloud-bigtable
Ideal Use Cases:
- Time-series data at massive scale
- IoT sensor data ingestion
- Financial market data
- AdTech and real-time bidding
- Clickstream analytics
- Graph data (adjacency lists)
- Large-scale machine learning features
Core Advantages:
- Google-grade reliability
- Consistent performance at scale
- Zero operational overhead
- Cost-effective for high-throughput workloads
- Automatic replication and backup
3.6 Best Graph Database: Neo4j AuraDB
Why It’s the Best: Neo4j pioneered the property graph model and remains the most mature graph database with the richest query language (Cypher) and ecosystem.
Strengths & Differentiators:
- Native graph storage: Optimized for traversals
- Cypher query language: Intuitive pattern matching
- ACID transactions: Full transaction support
- Performance: Constant-time traversals regardless of graph size
- Graph algorithms: Built-in library (shortest path, PageRank, community detection)
- Visualization: Excellent graph exploration tools
- Ecosystem: Largest graph database community
Cloud Availability:
- Neo4j AuraDB (AWS, Azure, GCP)
Python Driver:
neo4j(official driver)py2neo
Ideal Use Cases:
- Social networks and recommendations
- Fraud detection and network analysis
- Knowledge graphs
- Master data management
- Identity and access management
- Network and IT operations
- Supply chain and logistics
- Real-time recommendation engines
Core Advantages:
- Most expressive query language
- Best performance for connected data
- Mature tooling and visualization
- Strong ACID compliance
- Enterprise support
3.7 Best Time-Series Database: InfluxDB Cloud
Why It’s the Best: InfluxDB is purpose-built for time-series data with the most comprehensive feature set including retention policies, continuous queries, and native downsampling.
Strengths & Differentiators:
- Purpose-built: Optimized compression and indexing for time-series
- InfluxQL and Flux: Powerful query languages for time-series analysis
- High write throughput: Handles millions of writes per second
- Automatic downsampling: Reduce data granularity over time
- Retention policies: Automatic data expiration
- Alerting: Built-in monitoring and notifications
- Integrations: 300+ integrations with monitoring tools
Cloud Availability:
- InfluxDB Cloud (AWS, Azure, GCP)
- Amazon Timestream (alternative)
Python Driver:
influxdb-client
Ideal Use Cases:
- DevOps monitoring and observability
- IoT sensor data collection
- Application performance monitoring (APM)
- Network monitoring
- Industrial telemetry
- Energy and utilities monitoring
- Financial tick data
- Real-time analytics dashboards
Core Advantages:
- Best-in-class compression (10x typical databases)
- Purpose-built for time-stamped data
- Rich ecosystem of integrations
- Flexible data retention
- Easy to use and deploy
3.8 Best Search Engine: Elasticsearch
Why It’s the Best: Elasticsearch is the dominant search and log analytics platform, combining powerful full-text search with real-time analytics at scale.
Strengths & Differentiators:
- Distributed by design: Horizontal scaling built-in
- Near real-time search: Index and search in seconds
- Full-text search: Advanced relevance scoring and ranking
- Aggregations: Complex analytics across billions of documents
- Schema-free JSON: Flexible document structure
- Ecosystem: Kibana (visualization), Logstash (ingestion), Beats (shippers)
- Machine learning: Anomaly detection and forecasting
Cloud Availability:
- Elastic Cloud (AWS, Azure, GCP)
- Amazon OpenSearch Service
- Azure Cognitive Search
Python Driver:
elasticsearchopensearch-py(for OpenSearch)
Ideal Use Cases:
- Log and event aggregation (ELK stack)
- E-commerce product search
- Application search features
- Security analytics (SIEM)
- Business metrics and dashboards
- Content discovery
- Observability and APM
Core Advantages:
- Industry-standard for search
- Massive community and ecosystem
- Scales to petabytes
- Rich query DSL
- Real-time capabilities
3.9 Best Data Warehouse: Snowflake
Why It’s the Best: Snowflake revolutionized data warehousing with a cloud-native architecture that separates storage and compute, enabling unprecedented flexibility and performance.
Strengths & Differentiators:
- Separation of storage and compute: Scale independently, pay for what you use
- Zero management: No tuning, no indexing, fully managed
- Multi-cluster architecture: Concurrent workloads without contention
- Time travel: Query historical data up to 90 days
- Data sharing: Secure sharing across organizations without copying
- Semi-structured data: Native JSON, Avro, Parquet support
- Cross-cloud: Available on AWS, Azure, and GCP
- Instant elasticity: Resize warehouses in seconds
Cloud Availability:
- Snowflake (AWS, Azure, GCP)
Python Driver:
snowflake-connector-python- Snowpark (native Python processing)
Ideal Use Cases:
- Enterprise data warehousing
- Business intelligence and reporting
- Data science and machine learning
- Data lakes and lakehouses
- Large-scale ETL/ELT
- Multi-cloud analytics
- Data marketplaces
Core Advantages:
- Best price-performance ratio
- Zero operational overhead
- Instant scalability
- Near-unlimited concurrency
- Strong data governance
3.10 Best Multi-Model Database: Azure Cosmos DB
Why It’s the Best: Cosmos DB is the only globally distributed multi-model database that offers turnkey global distribution, multiple consistency levels, and comprehensive SLAs.
Strengths & Differentiators:
- Five data models: Document (SQL API), Key-Value (Table API), Graph (Gremlin), Column-Family (Cassandra API), MongoDB API
- Global distribution: One-click replication to any Azure region
- Five consistency levels: Choose from strong to eventual consistency
- Comprehensive SLAs: Latency, throughput, consistency, availability
- Multi-region writes: Active-active configuration
- Automatic indexing: No manual index management
- Serverless option: Pay per request
Cloud Availability:
- Microsoft Azure (60+ regions)
Python Driver:
azure-cosmos(SQL API)pymongo(MongoDB API)cassandra-driver(Cassandra API)gremlinpython(Gremlin API)
Ideal Use Cases:
- Global applications requiring low latency
- Applications with diverse data models
- IoT solutions at scale
- Real-time personalization
- Gaming leaderboards and profiles
- Retail and e-commerce
- Multi-tenant SaaS platforms
Core Advantages:
- True multi-model support
- Industry-leading global distribution
- Flexible consistency models
- Comprehensive SLAs
- Microsoft ecosystem integration
3.11 Best Embedded Analytics Engine: DuckDB
Why It’s the Best: DuckDB is a modern embedded OLAP database that brings data warehouse performance to your laptop, with zero configuration and zero dependencies.
Strengths & Differentiators:
- Columnar-vectorized engine: Optimized for analytical queries
- Zero configuration: Works out of the box
- In-process execution: No server, no network overhead
- SQL-first: PostgreSQL-compatible SQL dialect
- Direct file querying: Query Parquet, CSV, JSON directly
- Cloud integration: Read from S3, GCS, Azure Blob Storage
- Excellent Python integration: Seamless DataFrame interoperability
- Lightweight: Single binary, minimal footprint
Cloud Availability:
- Not cloud-hosted (embedded), but runs anywhere Python/SQL runs
- Can query cloud storage directly without data movement
Python Driver:
duckdb(native Python API)- Direct Pandas/Polars/Arrow integration
Ideal Use Cases:
- Data analysis in Jupyter notebooks
- ETL and data transformation
- Querying large CSV/Parquet files
- Embedded analytics in applications
- Data science workflows
- Prototyping data pipelines
- Local business intelligence
Core Advantages:
- Data warehouse speed without the infrastructure
- Perfect for data scientists and analysts
- Handles datasets larger than RAM
- Fast installation and zero setup
- Open source with strong community
3.12 Best Embedded OLTP Database: SQLite
Why It’s the Best: SQLite is the most widely deployed database engine in the world, running on billions of devices. It’s the default choice for embedded storage.
Strengths & Differentiators:
- Zero configuration: No setup, no server
- Single file: Entire database in one file
- Cross-platform: Runs on any OS
- Public domain: No licensing restrictions
- Reliable: Extensively tested, ACID-compliant
- Stable: Backward compatible for decades
- Small footprint: ~600KB compiled
- Excellent documentation: Comprehensive and clear
Cloud Availability:
- Not cloud-hosted (embedded)
- Runs on any VM, container, or edge device
Python Driver:
sqlite3(built into Python standard library)
Ideal Use Cases:
- Mobile applications (iOS, Android)
- Desktop applications
- Browser storage (via WASM)
- Embedded devices and IoT
- Configuration storage
- Application data persistence
- Testing and prototyping
- Small-to-medium websites
Core Advantages:
- Most ubiquitous database ever
- Zero operational cost
- Perfect for single-user applications
- Bulletproof reliability
- No network latency
4. Deep Differentiation Tables
4.1 Summary Comparison Across All Categories
| Category | Best Choice | Primary Strength | Scalability | Consistency | Query Complexity | Typical Latency |
|---|---|---|---|---|---|---|
| Relational | PostgreSQL | ACID + Flexibility | Vertical (good horizontal with extensions) | Strong | High | 1-10ms |
| Distributed SQL | Google Cloud Spanner | Global consistency at scale | Unlimited horizontal | Strong (globally) | High | 5-10ms |
| Document | MongoDB Atlas | Schema flexibility | Horizontal | Tunable | Medium-High | 1-5ms |
| Key-Value | Redis Enterprise Cloud | Speed | Horizontal | Tunable | Low | Sub-millisecond |
| Wide-Column | Google Bigtable | Write throughput | Horizontal | Eventual | Low-Medium | 1-10ms |
| Graph | Neo4j AuraDB | Relationship queries | Vertical + Sharding | Strong | High (for graphs) | 1-5ms |
| Time-Series | InfluxDB Cloud | Time-based analytics | Horizontal | Eventual | Medium | 1-10ms |
| Search | Elasticsearch | Full-text search | Horizontal | Near real-time | Medium | 10-100ms |
| Data Warehouse | Snowflake | Complex analytics | Elastic | Eventual | Very High | Seconds |
| Multi-Model | Azure Cosmos DB | Global distribution | Horizontal | Tunable (5 levels) | Medium | Single-digit ms |
| Embedded Analytics | DuckDB | In-process OLAP | Vertical (process-bound) | Strong | High | Microseconds |
| Embedded OLTP | SQLite | Simplicity + Portability | Vertical (file-based) | Strong | Medium | Microseconds |
4.2 SWOT Analysis by Category
Relational Databases (PostgreSQL)
| Strengths | Weaknesses |
|---|---|
| Mature, proven technology | Vertical scaling limitations |
| ACID guarantees | Schema changes can be disruptive |
| Rich query capabilities | Horizontal scaling requires effort |
| Strong data integrity | Can be overkill for simple use cases |
| Opportunities | Threats |
|---|---|
| Extensions (PostGIS, TimescaleDB) | NoSQL databases for specific workloads |
| Growing cloud adoption | Distributed SQL databases |
| JSON support bridges SQL/NoSQL gap | Serverless databases gaining traction |
Distributed SQL (Cloud Spanner)
| Strengths | Weaknesses |
|---|---|
| Global strong consistency | Higher cost than traditional databases |
| Unlimited scalability | Vendor lock-in (proprietary technology) |
| SQL semantics maintained | Learning curve for distributed concepts |
| 99.999% availability | Limited ecosystem compared to PostgreSQL |
| Opportunities | Threats |
|---|---|
| Growing need for global apps | Open-source alternatives (CockroachDB) |
| Cloud-native adoption | Cost-conscious customers |
| Regulatory requirements for data residency | Improved sharding in traditional databases |
Document Databases (MongoDB)
| Strengths | Weaknesses |
|---|---|
| Flexible schema | No schema enforcement (can be a con) |
| Excellent developer experience | Complex joins less efficient than SQL |
| Horizontal scalability | Eventual consistency by default |
| Rich query language | Data duplication common |
| Opportunities | Threats |
|---|---|
| Microservices architectures | PostgreSQL JSON support |
| Rapid development cycles | DocumentDB (AWS compatibility layer) |
| Mobile and IoT growth | Multi-model databases |
Key-Value Stores (Redis)
| Strengths | Weaknesses |
|---|---|
| Ultra-low latency | Limited query capabilities |
| Rich data structures | Memory-intensive |
| Simple data model | Not suitable for complex relationships |
| Excellent caching | Persistence trade-offs |
| Opportunities | Threats |
|---|---|
| Real-time applications growth | Alternatives like KeyDB |
| Edge computing | In-memory features in other databases |
| Microservices communication | Cloud-native caching services |
Wide-Column Stores (Bigtable)
| Strengths | Weaknesses |
|---|---|
| Massive scalability | No secondary indexes |
| High write throughput | Limited query flexibility |
| Low latency at scale | Schema design critical |
| Proven at Google scale | Steep learning curve |
| Opportunities | Threats |
|---|---|
| IoT explosion | Time-series-specific databases |
| Real-time analytics needs | Alternatives like ScyllaDB |
| Big data growth | ClickHouse for analytics |
Graph Databases (Neo4j)
| Strengths | Weaknesses |
|---|---|
| Relationship query performance | Niche use cases |
| Intuitive for connected data | Scaling challenges (compared to distributed DBs) |
| ACID transactions | Learning curve for Cypher |
| Rich visualization | Higher cost for enterprise features |
| Opportunities | Threats |
|---|---|
| Knowledge graphs gaining traction | Graph features in multi-model databases |
| AI and ML for recommendations | Amazon Neptune |
| Fraud detection demand | Graph extensions for PostgreSQL |
Time-Series Databases (InfluxDB)
| Strengths | Weaknesses |
|---|---|
| Optimized compression | Limited beyond time-series data |
| Purpose-built features | Clustering complexity (in some versions) |
| Excellent for monitoring | Not ideal for transactions |
| Auto-downsampling | Query language learning curve |
| Opportunities | Threats |
|---|---|
| IoT and monitoring growth | TimescaleDB (PostgreSQL extension) |
| Observability market expansion | Prometheus for metrics |
| Edge computing | ClickHouse for time-series |
Search Engines (Elasticsearch)
| Strengths | Weaknesses |
|---|---|
| Powerful full-text search | Resource-intensive |
| Near real-time indexing | Complex cluster management |
| Rich aggregations | Can be expensive at scale |
| Mature ecosystem | Steep learning curve |
| Opportunities | Threats |
|---|---|
| Log analytics growth | AWS OpenSearch (fork) |
| Application search demand | Specialized search services (Algolia) |
| Security analytics | Vector databases for semantic search |
Data Warehouses (Snowflake)
| Strengths | Weaknesses |
|---|---|
| Zero management | Can be expensive for continuous queries |
| Instant elasticity | Vendor lock-in |
| Excellent performance | Not suitable for OLTP |
| Storage/compute separation | Cost monitoring required |
| Opportunities | Threats |
|---|---|
| Data lakehouse architecture | BigQuery and Redshift |
| Data sharing economy | Open-source alternatives (Trino) |
| Cloud adoption | ClickHouse for specific workloads |
Multi-Model Databases (Cosmos DB)
| Strengths | Weaknesses |
|---|---|
| Multiple models in one system | Higher complexity |
| Global distribution | Can be costly |
| Flexible consistency | Azure-specific |
| Comprehensive SLAs | Not always best-in-class for each model |
| Opportunities | Threats |
|---|---|
| Simplifying architecture | Specialized databases outperform in their niche |
| Multi-region requirements | Multi-cloud strategies |
| Azure ecosystem growth | Open-source multi-model databases |
Embedded Analytics (DuckDB)
| Strengths | Weaknesses |
|---|---|
| Zero configuration | Single-process limitation |
| Analytical performance | Not for multi-user scenarios |
| Excellent Python integration | Limited ecosystem vs PostgreSQL |
| Portable | No built-in replication |
| Opportunities | Threats |
|---|---|
| Data science workflow integration | ClickHouse for larger deployments |
| Edge analytics | Polars for DataFrame operations |
| Embedded BI tools | In-database analytics in cloud warehouses |
Embedded OLTP (SQLite)
| Strengths | Weaknesses |
|---|---|
| Ubiquitous | Limited concurrency (writes) |
| Zero setup | No network access |
| Portable | Not for distributed scenarios |
| Public domain | Limited scalability |
| Opportunities | Threats |
|---|---|
| Mobile app growth | Cloud-based alternatives |
| Edge computing | Embedded alternatives (RocksDB) |
| WASM adoption | IndexedDB in browsers |
4.3 Performance & Trade-offs Table
| Database | Write Performance | Read Performance | Storage Efficiency | Operational Complexity | Cost (Relative) |
|---|---|---|---|---|---|
| PostgreSQL | Good | Excellent | Good | Low | Low |
| Cloud Spanner | Good | Excellent | Good | Very Low (managed) | High |
| MongoDB Atlas | Excellent | Excellent | Good | Low (managed) | Medium |
| Redis | Exceptional | Exceptional | Poor (in-memory) | Low | Medium-High |
| Bigtable | Exceptional | Excellent | Good | Very Low (managed) | Medium-High |
| Neo4j | Good | Excellent (graphs) | Medium | Medium | Medium-High |
| InfluxDB | Exceptional | Excellent (time queries) | Excellent | Low | Medium |
| Elasticsearch | Good | Excellent (search) | Medium | Medium-High | Medium-High |
| Snowflake | Good | Exceptional | Excellent | Very Low (managed) | Medium-High |
| Cosmos DB | Excellent | Excellent | Good | Low (managed) | High |
| DuckDB | Good | Exceptional | Excellent | Very Low | Free |
| SQLite | Good | Excellent | Excellent | Very Low | Free |
4.4 Full DuckDB vs SQLite Comparison
| Feature | DuckDB | SQLite |
|---|---|---|
| Primary Purpose | Embedded OLAP (analytics) | Embedded OLTP (transactions) |
| Storage Model | Columnar (optimized for analytics) | Row-based (optimized for transactions) |
| Query Optimization | Vectorized execution, optimized for aggregations | Index-based, optimized for lookups |
| Typical Query | SELECT category, SUM(sales) FROM orders GROUP BY category | SELECT * FROM users WHERE id = 123 |
| Performance Pattern | Fast on analytical queries (aggregations, scans) | Fast on transactional queries (point lookups, updates) |
| Concurrency | Read-optimized, limited write concurrency | Good read concurrency, single writer |
| File Format | Custom columnar format | B-tree row storage |
| In-Memory Mode | Excellent for medium datasets | Good for small datasets |
| File Querying | Direct Parquet/CSV/JSON querying | Requires import |
| Cloud Integration | Native S3/GCS/Azure support | None (file-based) |
| SQL Dialect | PostgreSQL-compatible | SQLite-specific |
| Joins | Optimized for large multi-table joins | Good for simple joins |
| Aggregations | Exceptional (core strength) | Adequate |
| Indexes | Automatic, minimal needed | Manual creation essential |
| Data Size Handling | Larger-than-RAM datasets | Best for datasets fitting in memory/disk |
| Python Integration | Seamless DataFrame support | Standard DB-API |
| Transaction Support | Yes (ACID) | Yes (ACID) |
| Use Case | Data analysis, ETL, BI queries | Application data, configuration, mobile apps |
| Deployment | Data science notebooks, analytical apps | Mobile apps, desktop software, browsers |
| Speed on Analytics | 10-100x faster than SQLite | Not optimized for analytics |
| Speed on Transactions | Adequate | Optimized |
| Ecosystem | Growing (data science focus) | Massive (ubiquitous) |
| Maturity | Young (2019) | Mature (2000) |
| License | MIT | Public Domain |
When to Choose DuckDB:
- Analyzing large CSV, Parquet, or JSON files
- Running complex analytical queries with aggregations
- Data science workflows in Python/R
- ETL and data transformation
- Querying data lakes directly
- Building embedded analytics features
When to Choose SQLite:
- Mobile or desktop application storage
- Configuration and settings persistence
- Single-user applications
- Browser-based storage (WASM)
- Embedded device data
- Simple CRUD operations
- When maximum compatibility is needed
Key Insight: They’re complementary, not competitors. SQLite excels at operational data (OLTP), DuckDB excels at analytical data (OLAP). Some applications use both.
5. Best Alternative to DuckDB: ClickHouse
Why ClickHouse?
While DuckDB is unbeatable for embedded analytics, ClickHouse is the best alternative when you need:
- Server-based deployment (not embedded)
- Multi-user concurrent access
- Distributed architecture for petabyte-scale data
- Real-time analytical dashboards
- Ultra-high compression ratios
ClickHouse Overview
What It Is: ClickHouse is an open-source columnar database designed for real-time analytical queries (OLAP). It’s the fastest database for analytical workloads at scale.
Key Strengths:
- Blazing speed: 100x-1000x faster than traditional databases for analytics
- Compression: 10-40x compression ratios
- Scalability: Linear scaling across hundreds of nodes
- Real-time: Ingests and queries data simultaneously
- SQL interface: Standard SQL with extensions
- Distributed: Built-in sharding and replication
Cloud Availability:
- ClickHouse Cloud
- Amazon, Azure, GCP (self-managed)
- Aiven for ClickHouse
- DoubleCloud
Python Connectivity:
clickhouse-driverclickhouse-connect
Use Cases:
- Web analytics (Cloudflare, Uber, eBay use it)
- Real-time dashboards
- Log analytics
- Time-series data at scale
- Event tracking
- Business intelligence
DuckDB vs ClickHouse Decision Matrix:
| Requirement | Choose DuckDB | Choose ClickHouse |
|---|---|---|
| Deployment | Embedded, in-process | Server-based, distributed |
| Users | Single user | Multiple concurrent users |
| Data Size | MB to GBs (100s of GB) | GB to petabytes |
| Infrastructure | None (embedded) | Cluster management |
| Query Latency | Microseconds (in-memory) | Milliseconds to seconds |
| Write Pattern | Batch loads | Continuous streaming |
| Use Case | Local analysis, notebooks | Production dashboards, APIs |
Bottom Line: If DuckDB’s single-process limitation becomes a bottleneck, ClickHouse is the natural next step for maintaining analytical performance at scale.
6. Master Summary
6.1 Condensed Comparison Table
| Category | Best Database | Key Strength | When to Use | When to Avoid |
|---|---|---|---|---|
| RDBMS | PostgreSQL | ACID + versatility | Structured data, complex queries | Extreme horizontal scale needed |
| Distributed SQL | Cloud Spanner | Global consistency | Multi-region apps, zero downtime | Cost-sensitive projects |
| Document | MongoDB | Schema flexibility | Rapid development, evolving models | Complex joins critical |
| Key-Value | Redis | Speed | Caching, real-time | Complex querying needed |
| Wide-Column | Bigtable | Write throughput | IoT, time-series at scale | Complex queries needed |
| Graph | Neo4j | Relationships | Connected data, social networks | Data mostly tabular |
| Time-Series | InfluxDB | Time-based queries | Monitoring, metrics | Non-temporal data |
| Search | Elasticsearch | Full-text search | Search features, log analytics | Primary database needs |
| Warehouse | Snowflake | Complex analytics | BI, data science | Real-time transactions |
| Multi-Model | Cosmos DB | Global distribution | Diverse data models, global apps | Single-region, single-model |
| Embedded Analytics | DuckDB | In-process OLAP | Data analysis, notebooks | Multi-user production |
| Embedded OLTP | SQLite | Simplicity | Mobile, desktop, edge | Multi-user server apps |
6.2 When to Choose Which Database — Cheat Sheet
I need to build a web application with user accounts and orders: → PostgreSQL (proven, reliable, handles relationships well)
I’m building a global SaaS application that must be fast everywhere: → Google Cloud Spanner (global consistency) or Cosmos DB (global distribution)
I’m creating a content management system with flexible content types: → MongoDB Atlas (schema flexibility, rapid iteration)
I need to cache database queries to speed up my application: → Redis Enterprise Cloud (sub-millisecond latency)
I’m building an IoT platform collecting millions of sensor readings per second: → Google Bigtable (extreme write throughput) or InfluxDB (if time-series-specific)
I’m building a social network or recommendation engine: → Neo4j AuraDB (optimized for relationships)
I need to monitor thousands of servers and applications: → InfluxDB Cloud (purpose-built for metrics) + Elasticsearch (for logs)
I’m adding search functionality to my e-commerce site: → Elasticsearch (full-text search champion)
I need to run complex analytics on years of sales data: → Snowflake (data warehouse performance and ease)
I want one database that can handle documents, graphs, and key-value data: → Azure Cosmos DB (multi-model flexibility)
I’m analyzing CSV files in a Jupyter notebook: → DuckDB (lightning-fast analytics, zero setup)
I’m building a mobile app that works offline: → SQLite (embedded, reliable, ubiquitous)
I need to analyze clickstream data for millions of users in real-time: → ClickHouse (real-time analytics at scale)
6.3 Decision Rules
By Data Characteristics
Highly structured, relational data:
- PostgreSQL (single server)
- Cloud Spanner (global scale)
Semi-structured, flexible schema:
- MongoDB Atlas
- PostgreSQL with JSONB
- Cosmos DB
Unstructured data:
- Elasticsearch
- MongoDB Atlas
Time-stamped data:
- InfluxDB Cloud
- TimescaleDB (PostgreSQL extension)
- Google Bigtable
Highly connected data:
- Neo4j AuraDB
- PostgreSQL with pg_graphql
By Scale & Performance Requirements
Sub-millisecond latency:
- Redis Enterprise Cloud
- DuckDB (in-process)
Millions of writes per second:
- Google Bigtable
- Apache Cassandra (not covered, but notable)
Petabyte-scale analytics:
- Snowflake
- Google BigQuery
- ClickHouse
Global distribution:
- Google Cloud Spanner
- Azure Cosmos DB
- MongoDB Atlas (Global Clusters)
By Operational Requirements
Zero management:
- SQLite (embedded, no server)
- DuckDB (embedded, no server)
- Snowflake (fully managed)
- Most cloud-managed services
Maximum control:
- Self-hosted PostgreSQL
- Self-hosted MongoDB
- Self-hosted ClickHouse
Multi-cloud strategy:
- Snowflake (AWS, Azure, GCP)
- MongoDB Atlas (AWS, Azure, GCP)
- ClickHouse Cloud
By Budget
Free/Open Source:
- PostgreSQL
- SQLite
- DuckDB
- Self-hosted MongoDB, Redis, ClickHouse
Cost-effective cloud:
- DigitalOcean Managed Databases (PostgreSQL)
- MongoDB Atlas (free tier available)
- Amazon RDS
Premium (value for features):
- Google Cloud Spanner
- Snowflake
- Azure Cosmos DB
By Use Case
E-commerce:
- PostgreSQL (transactions) + Redis (caching) + Elasticsearch (search)
Social Network:
- Neo4j (relationships) + Redis (feeds) + PostgreSQL (user data)
IoT Platform:
- Google Bigtable or InfluxDB (ingestion) + Snowflake (analytics)
Content Management:
- MongoDB Atlas (flexible content) + Elasticsearch (search)
Real-time Analytics Dashboard:
- ClickHouse + Redis
Data Science Workflow:
- DuckDB (analysis) + PostgreSQL (results storage)
Mobile App:
- SQLite (local) + MongoDB Atlas (sync) + Redis (caching)
7. Final Notes
Key Takeaways
No single database is perfect for everything. Choose based on your specific requirements: data model, scale, consistency needs, and budget.
Start simple. PostgreSQL or MongoDB Atlas covers 80% of use cases. Optimize when you have real performance data.
Embedded databases (SQLite, DuckDB) are underrated. They eliminate operational complexity and network latency.
Cloud-managed services reduce operational burden significantly. Unless you have specific requirements, prefer managed offerings.
Polyglot persistence is normal. Modern applications often use multiple databases: PostgreSQL for transactions, Redis for caching, Elasticsearch for search.
Consider your team’s expertise. A familiar database your team knows well often outperforms an “optimal” but unfamiliar choice.
Data modeling matters more than database choice in many cases. Poor schema design will hurt performance regardless of technology.
Test before committing. Most databases offer free tiers or trials. Benchmark with your actual workload.
Python Ecosystem Summary
All databases mentioned have mature Python support:
Standard DB-API 2.0 compliant:
- PostgreSQL (
psycopg3) - SQLite (
sqlite3) - Most SQL databases
Native Python APIs:
- MongoDB (
pymongo) - Redis (
redis-py) - DuckDB (
duckdb) - Neo4j (
neo4j) - InfluxDB (
influxdb-client) - Elasticsearch (
elasticsearch)
Cloud SDKs:
- Google Cloud (
google-cloud-bigtable,google-cloud-spanner) - Azure (
azure-cosmos) - AWS (
boto3for DynamoDB, Timestream, etc.)
ORMs & Abstractions:
- SQLAlchemy: Universal ORM for SQL databases
- Django ORM: Built-in ORM for web applications
- Peewee: Lightweight ORM
- MongoEngine: ODM for MongoDB
- Pandas/Polars: DataFrame integration with DuckDB, SQLite
Further Reading
Official Documentation:
Database Comparisons:
Learning Resources:
- SQLBolt (Interactive SQL Tutorial)
- MongoDB University (Free Courses)
- Use The Index, Luke (SQL Performance)
Benchmarks & Performance:
Document Version: 1.0
Last Updated: November 2025
Compatibility: Chirpy/Jekyll Markdown